728x90
Scikit-Learn을 사용하여 지도 학습(Seupervised Learning) 모델을 만들어 보자.

Linear Regression(선형 회귀)
- 종속 변수와 한 개 이상의 독립 변수와의 선형 상관 관계를 모델링하는 회귀 분석 기법
- 판매, 연봉, 나이, 제품 가격 등과 같은 수치를 예측한다.
- Scikit-Learn에서 Linear Regression 모델을 사용해서 불러온다.
Boston 집값 데이터를 사용하여 모델을 만들어 보자.
#우선 필요한 패키지를 불러온다.
import numpy as np
import pandas as pd
import sklearn
import matplotlib.pyplot as plt
# warning 메시지 무시하기. 불필요하게 나오는 경우가 있기 때문
import warnings
warnings.filterwarnings('ignore')
# 보스턴 집값 데이터 불러오기
from sklearn.datasets import load_boston
boston = load_boston()
#Description를 확인해 보자.
print(boston['DESCR'])>>

■ 필요한 데이터 추출하기
data = boston.data #data = boston['data']로 써도 됨
label = boston.target
columns = boston.feature_names
■ DataFrame 객체로 만들기
data = pd.DataFrame(data, columns=columns)
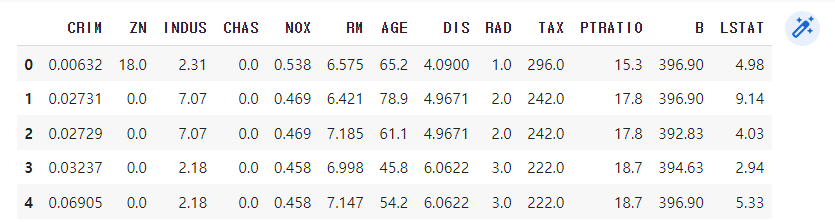
■ data head 정보 살펴보기
data.head()
>>
# data shape 살펴보기
data.shape
>> (506, 13)
# 이제 Simple Linear Regression를 해 보자.
# 데이터 준비하기(쪼개기)
from sklearn.model_selection import train_test_split
# 학습용 데이터, 테스트용 데이터, 학습용 라벨, 테스트용 라벨
# 제일 처음 data를 주고, 그 다음으로는 label, 테스트 용도로는 20%정도만,
# random 값 주기: 2022부터 섞어주세요
X_train, X_test, y_train, y_test= train_test_split(data, label, test_size=0.2, random_state=2022)
# RM 값(방의 개수) 하나만 가지고 예측해 보자.
print(X_train['RM'])
>>
256 7.454
288 6.315
318 6.382
136 5.942
233 8.247
...
177 6.315
112 5.913
173 6.416
220 6.951
381 6.545
Name: RM, Length: 404, dtype: float64
[10]
[20]
[30]
[10, 20, 30
= (1,)
# 위와 같은 1차원 배열의 나열은 학습에 쓸 수 없다.
# [[10], [20]]과 같은 2차원 배열로 바꿔주기 = (1, 2)
# 데이터를 잘랐으므로 506개가 아님. 데이터의 전체 개수는 0~x까지인데,
# -1을 해주면 0에서 끝으로 돌아가 자른 데이터의 개수를 알 수 있다.
# 즉, (-1, 1)은 처음부터 끝까지의 개수를 알 수 있는 좌표!
X_train['RM'].values.reshape(-1, 1)
# 전체를 다 볼 필요는 없으므로 슬라이스를 사용한다.
X_train['RM'].values.reshape(-1, 1)[:5]
>>
array([[7.454], [6.315], [6.382], [5.942], [8.247]])
# Linear Regression 알고리즘 불러오기
from sklearn.linear_model import LinearRegression
sim_lr = LinearRegression()
# 학습(훈련)시키기
# 데이터와 라벨값(y_train)을 주어야 하는데 아까 1차원이었으므로
# 2차원으로 reshape해줘야 하는 것 잊지 말자.
sim_lr.fit(X_train['RM'].values.reshape((-1,1)) ,y_train)
# 참고: reshape((2, 3)) 2행 3열 2차원 배열, reshape((2, 3, 1)) 2행 3열 1깊이의 3차원 배열
# 결과 테스트해 보기
y_pred = sim_lr.predict(X_test['RM'].values.reshape((-1,1)))■ 결과 확인하기
>>

# 테스트용 데이터를 가지고 실질적으로 확인해 보자.
# R2(R Squared, R^2, 결정계수)로 원본 라벨 데이터(y_test)와 예측값(y_pred) 차이 비교하기
from sklearn.metrics import r2_score
print('단순 선형 회귀, R2: {:.4f}'.format(r2_score(y_test, y_pred)))
# .4는 소수점 넷째짜리까지, f는 실수형
>> 단순 선형 회귀, R2: 0.2121결과가 매우 매우 좋지 않다.

그럼 matplotlib을 사용하여 결과를 시각화하여 자세히 살펴보자.
matplotlib으로 산점도(scatter plot)그리기
*맨 처음 미리 import 해 두었음.
- X축: RM 개수
- y축: Price
- 범위: min~max 설정. 방의 개수가 가장 적은 집~방의 개수가 가장 많은 집
- min과 max 사이에 점을 몇 개 찍을지 설정한다.
line_X = np.linspace(np.min(X_test['RM']), np.max(X_test['RM']), 10)
line_y = sim_lr.predict(line_X.reshape(-1,1))
# 어떻게 그릴지 설정
plt.scatter(X_test['RM'], y_test, s=10, c='black')
plt.plot(line_X, line_y, c='red')
# 각주 표시
plt.legend(['Regression line','Test data sample'], loc='upper left')>>
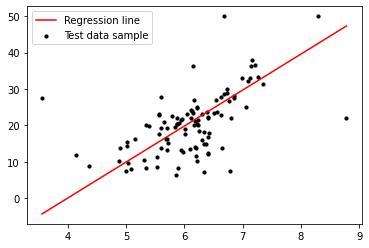
너무 분산되어 나온 것을 알 수 있다. Room 개수 하나만 가지고 평가하기 부족하다.
RM 하나의 column 말고 전체 columns를 가지고 모델을 만드는 것이 좋겠다!
728x90
'MS AI School' 카테고리의 다른 글
| DAY 21 - 머신러닝 지도 학습: 분류(Classification) (0) | 2022.11.23 |
|---|---|
| DAY 20 - 머신러닝 지도 학습: 결정 트리 모델, SVM, 다중 MLP 회귀 (0) | 2022.11.23 |
| DAY 18 - Scikit Learn 머신러닝 모델 만들기 (0) | 2022.11.01 |
| DAY 15 - Feature와 Label, Data Preprocessing(데이터 전처리) (0) | 2022.11.01 |
| DAY 14 - Flask, Web crawling(BS4), MySQL (0) | 2022.11.01 |