전처리 되어 있는 데이터를 가지고 이진 분류 모델 만들기
원 핫 인코딩
import keras
print(keras.__version__)from keras.datasets import imdb
(train_data, train_labels),(test_data, test_labels) = imdb.load_data(num_words=10000)train_data.shape>> (25000,)
train_data[0]>> [1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50,
16, 5345, 19, 178, 32]
train_labels[0]>> 1
word_index = imdb.get_word_index()
word_index.items()
reverse_word_index = dict([value, key] for (key, value) in word_index.items())word_index는 단어를 정수 인덱스에 매핑하는 것. 모델의 예측 결과를 보기 위해 이 인덱스 시퀀스를 다시 사람이 읽을 수 있는 단어 시퀀스로 변환할 필요가 있다. 따라서 reverse_word_index를 만들어 정수 인덱스를 단어로 매핑하여 사람이 읽을 수 있는 형태로 디코딩할 수 있도록 한다.
decoded_review = ' '.join([reverse_word_index.get(i-3,'?') for i in train_data[0]])
decoded_review>> "? this film was just brilliant casting location...
'i-3'은 특수 토큰의 인덱스를 조정하기 위해 3을 뺀 값. IMDB 데이터셋에서는 0, 1, 2가 각각 패딩<PAD>, 문장의 시작<SOS>, 사전에 없는 단어<UNK>를 나타내는 특수 토큰. 키가 존재하지 않을 경우 get() 메서드를 사용하여 '?'를 반환시킨다. 이는 해당 인덱스가 사전에 없는 단어이거나 특수 토큰임을 나타낸다.
# 데이터 준비
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences),dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1
return results
# Data의 Encoding
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)result 배열은 len(sequence) 행과 dimension 열을 가지며 모든 요소가 0으로 초기화되어 있다. 이 배열은 각 시퀀스를 벡터화한 결과를 저장하는 용도로 사용된다.
등장한 단어의 위치에 해당하는 열의 값을 1로 설정하고, 등장하지 않은 단어의 위치는 0으로 설정한다.
print(x_train[0])>> [0. 1. 1. ... 0. 0. 0.]
# float type으로 변환
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')Why? 이진 분류 문제에서 주로 신경망 모델의 출력 레이어의 활성화 함수로 시그모이드 함수를 사용하기 때문. 시그모이드 함수는 0과 1 사이의 값을 출력하는 함수이다.
# 신경망의 구축
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))ReLU는 입력값이 0보다 작은 경우 0으로 변환, 0보다 큰 경우에는 입력값을 유지.
Sigmoid는 0과 1 사이의 값으로 변환
from tensorflow.keras import optimizers
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss='binary_crossentropy',
metrics=['accuracy'])x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))>>
Epoch 1/20
30/30 [==============================] - 2s 59ms/step - loss: 0.5062 - accuracy: 0.7899 - val_loss: 0.3772 - val_accuracy: 0.8733
Epoch 2/20
30/30 [==============================] - 1s 44ms/step - loss: 0.3022 - accuracy: 0.9040 - val_loss: 0.3185 - val_accuracy: 0.8750
Epoch 3/20
30/30 [==============================] - 1s 38ms/step - loss: 0.2219 - accuracy: 0.9285 - val_loss: 0.2925 - val_accuracy: 0.8816
Epoch 4/20
30/30 [==============================] - 4s 122ms/step - loss: 0.1718 - accuracy: 0.9454 - val_loss: 0.2766 - val_accuracy: 0.8902
Epoch 5/20
30/30 [==============================] - 1s 48ms/step - loss: 0.1398 - accuracy: 0.9566 - val_loss: 0.2910 - val_accuracy: 0.8893
Epoch 6/20
30/30 [==============================] - 1s 37ms/step - loss: 0.1146 - accuracy: 0.9663 - val_loss: 0.2962 - val_accuracy: 0.8867
Epoch 7/20
30/30 [==============================] - 1s 34ms/step - loss: 0.0927 - accuracy: 0.9735 - val_loss: 0.3211 - val_accuracy: 0.8850
Epoch 8/20
30/30 [==============================] - 1s 35ms/step - loss: 0.0746 - accuracy: 0.9808 - val_loss: 0.3441 - val_accuracy: 0.8836
Epoch 9/20
30/30 [==============================] - 1s 33ms/step - loss: 0.0635 - accuracy: 0.9820 - val_loss: 0.3556 - val_accuracy: 0.8793
Epoch 10/20
30/30 [==============================] - 1s 34ms/step - loss: 0.0476 - accuracy: 0.9896 - val_loss: 0.3822 - val_accuracy: 0.8765
Epoch 11/20
30/30 [==============================] - 1s 34ms/step - loss: 0.0402 - accuracy: 0.9919 - val_loss: 0.4100 - val_accuracy: 0.8755
Epoch 12/20
30/30 [==============================] - 1s 34ms/step - loss: 0.0318 - accuracy: 0.9940 - val_loss: 0.4417 - val_accuracy: 0.8775
Epoch 13/20
...
Epoch 19/20
30/30 [==============================] - 1s 34ms/step - loss: 0.0074 - accuracy: 0.9986 - val_loss: 0.6714 - val_accuracy: 0.8677
Epoch 20/20
30/30 [==============================] - 1s 33ms/step - loss: 0.0027 - accuracy: 0.9999 - val_loss: 0.6989 - val_accuracy: 0.8684# 실험 결과 데이터를 가져온다.
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc)+1) # 끝 값을 포함# 실험 결과를 시각화 한다.
import matplotlib.pyplot as plt
plt.plot(epochs, loss, 'bo', label='Training Loss')
plt.plot(epochs, val_loss,'b-', label='Validation Loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()bo: blue 원형 마커
b-: blue 선 마커

plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b-', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()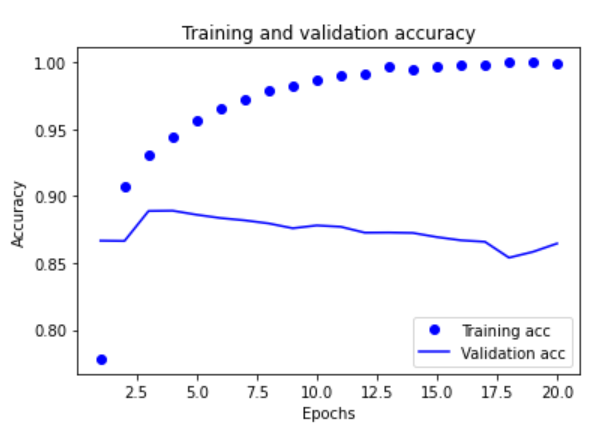
history = model.fit(partial_x_train,
partial_y_train,
epochs=3,
batch_size=256,
validation_data=(x_val, y_val))Epoch 1/3
59/59 [==============================] - 2s 24ms/step - loss: 0.4716 - accuracy: 0.8121 - val_loss: 0.3322 - val_accuracy: 0.8826
Epoch 2/3
59/59 [==============================] - 1s 18ms/step - loss: 0.2526 - accuracy: 0.9112 - val_loss: 0.2824 - val_accuracy: 0.8893
Epoch 3/3
59/59 [==============================] - 1s 20ms/step - loss: 0.1817 - accuracy: 0.9371 - val_loss: 0.2760 - val_accuracy: 0.8901'MS AI School' 카테고리의 다른 글
| DAY 33 - 회귀 실습(보스턴 집값 예측) (0) | 2022.12.07 |
|---|---|
| DAY 32 - 다중 분류 실습(로이터 기사) (0) | 2022.12.06 |
| DAY 30 - 모델 저장 및 불러오기 .PKL (0) | 2022.12.06 |
| DAY 29 - Docker 도커? (0) | 2022.12.06 |
| DAY 28 - 딥러닝 Training 과정 (0) | 2022.12.06 |